
AI technology, a key driver of the Fourth Industrial Revolution, is transforming global industries. OpenAI’s ChatGPT, launched in late 2022, sparked the AI 2.0 era, offering tools for language processing, image and video generation, and coding. This advancement has fueled widespread business interest in generative AI (GenAI), making AI computing power a critical measure of national competitiveness. According to IDC’s 2022-2023 Global Computing Power Index, the AI computing market is set to grow from $19.5 billion in 2022 to $34.66 billion by 2026, with the generative AI market expanding from $820 million to $10.99 billion during the same period.
Professor Tien-Fu Chen, Vice Dean of the College of Computer Science (CCS) at National Yang Ming Chiao Tung University (NYCU) notes that governments are investing in AI computing centers, like Taiwan’s AI supercomputer “Taiwania 2,” developed by the National Center for High-Performance Computing. However, the AI industry faces challenges, including the dominance of NVIDIA in the GPU market, which has resulted in high costs and chip shortages.

As companies like AMD, Intel, Meta, and Google develop their own AI architectures to reduce costs, the AI chip shortage is expected to ease. The three essential pillars for successful AI projects—data, algorithms, and computing power—are more critical than ever.
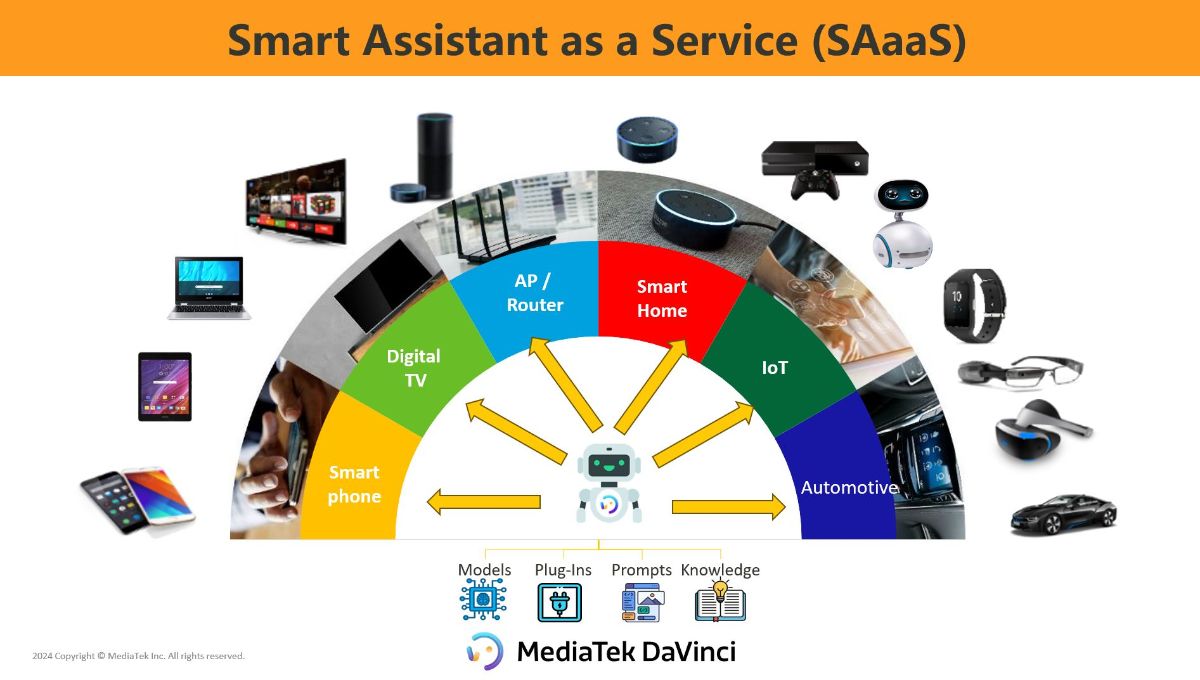
Many companies are already integrating GenAI into their operations to boost efficiency, quality, and reduce costs. MediaTek’s DaVinci platform, initially designed to enhance internal productivity, has grown into an ecosystem for businesses in sectors such as technology, finance, and education. However, adopting GenAI is no longer optional. Companies that fail to adapt risk falling behind. For effective implementation, businesses need diverse datasets, advanced AI algorithms, and powerful computing platforms to avoid delays and align with industry progress.
Data preparation is key to the success of AI projects. However, many companies struggle with organizing usable data, which impacts the effectiveness of AI model training. AI-powered data-cleaning tools can significantly streamline this process, ensuring better data quality and faster results. Professor Chen highlights the importance of cross-departmental collaboration, leveraging industry expertise to enhance data cleaning and GenAI project success.
For businesses new to GenAI, open-source large language models (LLMs) offer a cost-effective alternative to in-house training. By combining these models with internal data, companies can reduce infrastructure costs and accelerate project timelines. Popular open-source models like BLOOM, LLaMA3, and Mistral are already widely adopted, offering flexibility based on specific needs.
Additionally, companies can minimize the learning curve and avoid costly errors by partnering with external AI experts. These experts provide comprehensive solutions, from platform setup to project consulting, helping businesses implement AI technology more effectively without significant upfront investment.
As AI adoption grows, the demand for skilled talent has surged. Companies are increasingly collaborating with research institutions to train employees as AI experts. This strategy not only enhances workforce capabilities but also helps businesses navigate the challenges of AI project execution.
Professor Chen emphasizes that GenAI projects require time for results. Companies should focus on gradual improvements rather than expecting overnight transformations. With platforms like NYCU’s myLLM industry-academia alliance, businesses can accelerate their AI initiatives and evaluate further investments in GenAI for sustained digital transformation.
